Today, We will take a look at concept called Branch Predictors which is used inside of modern processors. This is important concept in Processor Architecture. I will be using RISC-V and Rust to explain my thinking but don't be intimidated by it. Just read it bit by bit and you shall too flow along.
What is a branch ? #
Well in higher level languages we call things as if-else statements. Those same statements in lower languages are called branch. Refer the below code
1let x = 10;
2if x==10{
3 x = x+1
4}
Now in low level for example in RISC-V code this can be expressed as below
ld x1, 10
BEQ x1, 10, equal
equal:
addi x1, x1, 1
In order to understand branch predictors it is really important to understand about Pipelining architecture which is used in RISC-V processors.
What is Pipelining #
Processor pipelining is a technique used in modern computer processors to improve their efficiency by breaking down the execution of instructions into multiple stages. Think of it like an assembly line in a factory, where different workers perform different tasks on a product as it moves through various stations.
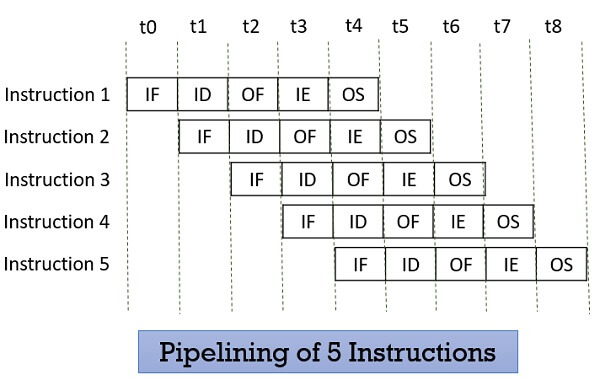
With pipelining, There comes the problem of Hazards.
Hazards refer to situations where the execution of instructions does not proceed as smoothly as intended, leading to incorrect results or performance slowdowns.
-
Data Hazards: These occur when instructions depend on the results of previous instructions. You cannot proceed further unless you have data which is still being computed in previous instruction.
-
Conditional Hazards: They happen specifically when a branch instruction is dependent on the result of a preceding instruction. The issue is that the processor may not know whether to take the branch until after the instruction has progressed through some pipeline stages, causing a potential delay or misprediction.
In the above example, If branch was to be taken then we can add 1 to x1. But what if it was not taken? Without any branch predictor circuit, All you can do is wait untill you are given the result saying that "please take the branch" or "please don't take the branch".
Branch Prediction #
In order to speed up the process, You can implement the branch predictor circuit. The core principle of branch predictor is that you assume the result and move ahead with it. In case it was correct, You will get the fast performance. But if it turns out to be incorrect then you have to come back and re-do your work.
This is not some random stuff. You still maintain the history for the branch whether it was taken or not and store in Lookaside Branch Tables. Based on your outcome you decide the next time if you should take it or not. As your code grows large, There are more chances of success for your performance to improve. In worst case, It only takes one extra cycle to recover from wrong predictions where Branches are executed. On an average 17% overhead is increased with wrong prediction. But improved with better correction mechanism.
1-Bit Branch Predictors #
In initial processors, There used to be 1-bit branch predictors.
1let taken = false; // Assume by default branch as not taken
2while instructions!=null { // While Instruction keeps running
3 // Move ahead with next instruction assume branch as not taken
4}
5// Now you receive the result
6if taken = true {
7 // Redo while loop
8}else {
9 // Skip this and go ahead in pipeline
10}
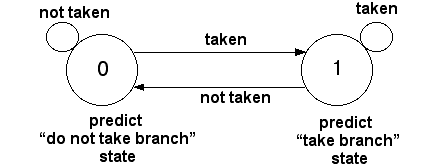
Problem
Consider the scenario where one bit is assumed to be taken for n times. Then the very next bit is not taken. Eg :
- Predicted Value :
T T T _T _N _T _N _T - Reality Decision:
T T T _N _T _N _T _N
Here if you observe, starting from 4th position, The decision has been inverted and things have started tuning down for further decisions. Then for the very next iteration, You would assume this to be as wrong by inverting your decision. The wrong predictions are marked with underscore(_). There are 5 wrong predictions. Accuracy is 50%.
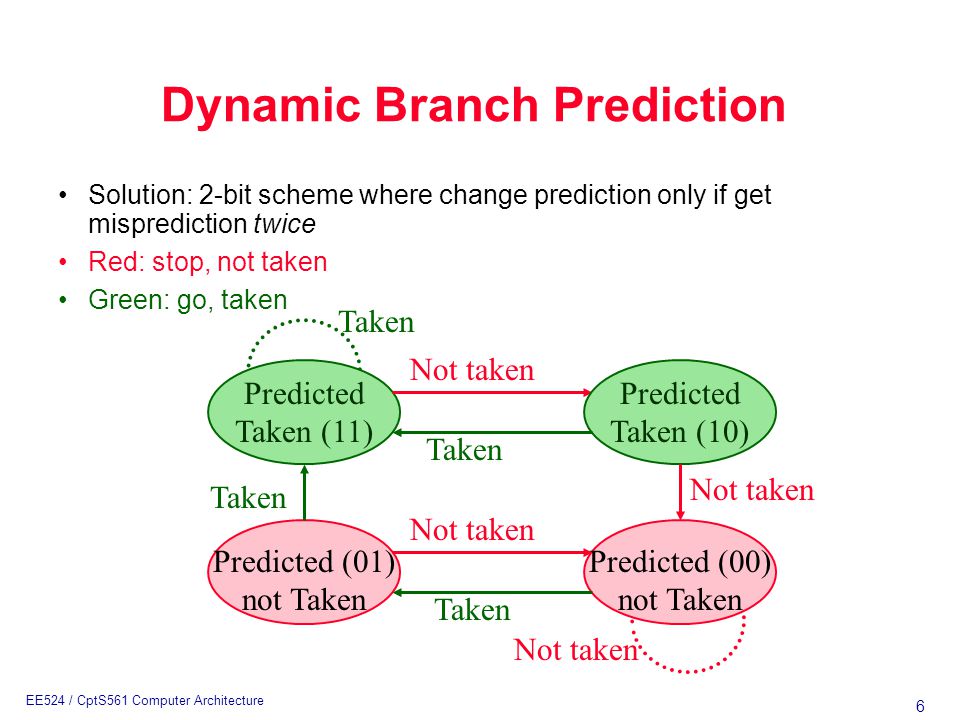
2-Bit predictor #
The above problem of 1-bit predictor is solved by 2-bit predictor. This goes by the principle that when there are two wrong bits then only invert the result. Otherwise keep the predicition same
- Predicted Value :
T T T _T T _T T _T - Reality Decision:
T T T _N T _N T _N
The number of wrong predictions now are reduced to 3. So you have 7 correct predictions and 3 wrong. Accuracy is 70%. This improves the performance of the pipeline. We should only invert in case of two wrong decisions which i snot happening in the above case hence we have never updated the prediction bit.
This was a beautiful concept of optimizing the performance of Processor which I found while learning about this in my Processor Architecture class. Also few days back, I was wondering about why would compilers need something like an ML/AI tech into it. It was very very unclear for me. But, As I learn more about the Processor Architecture principles and VLSI design, I have started to understand the need of cross-tech integration. This was a beautiful combination of how previous predictions can affect future one. This could potentially be converted into any ML prediction model with overhead of increased hardware but to the very least I have started gaining the interest in smart compilers. It is the real use of upper stack to improve the device and hardware.
Thanks a lot for sticking around to read this.